Scanning a Disk for Bad Sectors
Every operating system has tools to scan a disk for bad sectors. Some are automatically invoked during startup if the computer detects an improper shutdown. For example, Windows maintains a “dirty bit” in the Master File Table (MFT) on NTFS volumes or the File Allocation Table (FAT) on FAT16/32 drives.
During boot, the autochk program looks for this value and if it is set, it will run an abbreviated version of the actions performed by chkdsk on all volumes flagged. A similar process is used by other modern operating systems.
Windows
For those who are not afraid of the Windows command line, chkdsk /r or chkdsk /b can be run at any time to look for bad sectors. It will run other tests first to verify the consistency of the drive’s metadata before the optional bad sector pass. Depending on the size of the volume in question and the number of directories and files, it can take quite some time to complete. The difference between the two commands is the second one will re-evaluate sectors that are already flagged by the operating system as bad.
Windows also has a GUI tool that can be used to perform the same checks. It can be accessed by opening Windows Explorer > right-click the drive to check >Properties > Tools tab > Check now… > check “Scan for and attempt recovery of bad sectors” > Start.
No matter which one you choose, if you are scanning a system or boot drive, it will require exclusive access to the volume and ask you if you want to schedule the scan on the next restart. If it is not a system drive, the scan should begin immediately unless another process has already locked it for exclusive access.
This tool does not mark individual sectors bad; it marks the entire cluster as bad in the MFT or FAT and relocates the entire cluster to another unused cluster on the drive. This can happen if the drive hardware cannot remap the bad sector for any reason such as its spare sector pool has been exhausted.
Linux
Although the badblocks program can be used to search for bad blocks (sectors) on a disk partition on Linux systems, I recommend you use e2fsck -c instead or the appropriate fsck variant for the filesystem you are using. This ensures that the proper parameters are passed to the badblocks program.
Incorrect parameters can cause irreparable damage to the filesystem. The -cparameter performs a read-only test on the volume. If you want to use a non-destructive read-write test, you need to specify the -cc parameter instead.
When using -c or -cc, the entire bad blocks list is rebuilt. If you wish to keep the existing entries in the list and merely append new blocks to the list, add the -k (keep) option. If you suspect there has been damage to the drive itself and/or the filesystem, you may also want to add the -p (preen) option which will attempt to automatically repair any damage. It will notify you if it cannot fix errors it finds.
Manufacturer Tools
Drive manufacturers have their own diagnostic software that may be used to perform surface analysis and control features specific to their drives. Western Digital has Data Lifeguard for Windows for their drives while Seagate has SeaTools for Windows which can be used to test Seagate, Maxtor, and Samsung drives.
Both offer options for testing and repairing their associated drives but you need to be careful about what tests are destructive and which are non-destructive. In either case, you should still have a current backup before proceeding.
Third-party Tools
There are also third-party tools such as SpinRite from Gibson Research Corporationthat access the drive below the operating system level in order to perform their magic. It bypasses BIOS and interacts directly with the hard drive controller. It is primarily for data recovery but can also be used to perform surface analysis and verification prior to putting a new drive into service.
SpinRite does have its limitations. Because it runs on the FreeDOS operating system and it uses CHS to access the drive, it can only access the first 228 (268,435,456) sectors. So a drive that uses 512 byte sectors will be limited to 128 GB and a drive using 4K sectors will be restricted to 1 TB.
By setting it up on a bootable disk using the Windows 98 DOS 7 command interpreter, SpinRite 6 can theoretically test the entire drive.
Are Bad Sectors Repairable?
Physical defects from manufacturing, head crashes and most other faults detected by the hard disk controller generally cannot be repaired. Those that have been isolated by the operating system are another story.
Operating System Tools
It is sometimes possible to recover blocks or clusters that have been marked as bad by the operating system. Since a cluster is normally several sectors and a single bad sector will get an entire cluster marked as bad, it is occasionally possible to recover those clusters.
This is because the hard drive controller may not have dealt with the bad sector before the operating system had a problem with it. Remember, the drive generally doesn’t know something is wrong until it cannot read the sector and it does not attempt to remap the sector unless there are numerous failed reads or a write is attempted to that sector after a failed read.
If the hard drive controller has reallocated the bad sector after the operating system marked the containing cluster as bad, re-running the appropriate command to re-evaluate the bad blocks (chkdsk /b for Windows, e2fsck -cc for Linux – you must not use the -k option here since it would keep the current list of bad blocks) should clear it from the list.
SpinRite
SpinRite is one of the tools that claims to be able to recover weak sectors. Even with three decades of working with technology, this is something I am unwilling to trust. The sector was originally marked as bad by the drive controller (or the containing cluster was marked by the operating system) because data could not be reliably read from it. Even if its ability to retain data can be improved, it is likely to be temporary which should bring a couple questions to mind.
- How temporary is this repair?
- Are you willing to trust your data to this sector?
Personally, this is one area where I am unwilling to tread. Much of my data is too important.
Monitoring Drive Status
One of the two best ways to protect the data you have stored on your drives – if you haven’t discerned it from previous comments – is to ensure you have implemented a reliable backup plan.
The other is using software to monitor the status of your drives. Modern hard drives include Self-Monitoring, Analysis and Reporting Technology (SMART) to help determine the health of the drive and predict failures.
Ubuntu, RedHat, and their derivatives have the Disks utility as part of their default installation. It allows you to access the most important SMART counters as well as run both the short and extended SMART tests. There are also command line tools such as smartctl which can be used to automate checking and reporting of drive status.
Windows does not supply this capability so we need third-party tools such asCrystalDiskInfo and Hard Disk Sentinel to handle the job.
SMART Counters
Don’t freak out when you see the values being reported by these tools. The threshold value is set by the manufacturer to indicate when it will be considered a problem. The current normalized value is likely to be higher than the worst reported value and for most counters this is expected. The normalized values which range from 1 to 253, although some manufacturers will choose a starting point of 100 or 200 for some attributes, decrease from a higher starting point over time and it isn’t necessarily a problem until it goes below the threshold value.
No matter what tool you choose to use to monitor your storage devices, there is a short list of counters you should be concerned with provided your drive supports them:
- Counter 5 (Reallocated Sectors Count) is a total count of sectors that have been reallocated and placed on the G-LIST since it was put into service. This does not include the sectors that were flagged at the factory. The raw data is a true count so lower is better.
- Counter 10 (Spin Retry Count) indicates how many times the drive needed to try to spin up the drive until it reached operational speed if the first try was unsuccessful. Increases in this attribute indicate mechanical issues with the drive or a possible power problem.
- Counter 187 (Reported Uncorrectable Errors) is the number of ECC errors that could not be fixed by the drive controller. Lower is better when looking at the raw value.
- Counter 188 (Command Timeout) is the number of aborted operations on the device. This is commonly a result of problems with the power supply or data cable connection issues. Again, the raw data value should be low.
- Counter 195 (Hardware ECC Recovered) is a vendor-specific implementation so the values may not always represent identical conditions. In general, it is a count of the number of times ECC correction was required to return the correct data from the drive.
- Counter 196 (Reallocation Event Count) represents the number of times sectors have triggered a remap event by the controller. It counts both successful and unsuccessful attempts to remap sectors. It is not supported by all manufacturers.
- Counter 197 (Current Pending Sector Count) is the number of sectors that are currently marked as unstable and will be remapped if its next read attempt is successful or when it is next written. This counter is decremented once the sector has been successfully remapped.
- Counter 198 (Offline Uncorrectable Sector Count) is the total count of errors when reading or writing sectors. If this starts going up, there is a problem with the disk surface or the mechanical subsystem.
Taken by themselves, many of the counters available don’t offer much insight into the overall health of your drives. But when they are taken together, paying particular interest to the ones listed above, you are more likely to spot negative trends so you can prepare for the drive’s inevitable demise.
Conclusion
Even though there are tools available to help predict how much life may be left in your storage devices, it does not obviate the need for a solid, tested backup plan.There is evidence that a large number of drives will fail without a single SMART error appearing in its entire history. In the same report, it also shows a high correlation between some of the SMART errors listed above and an extremely abbreviated lifespan of the device.
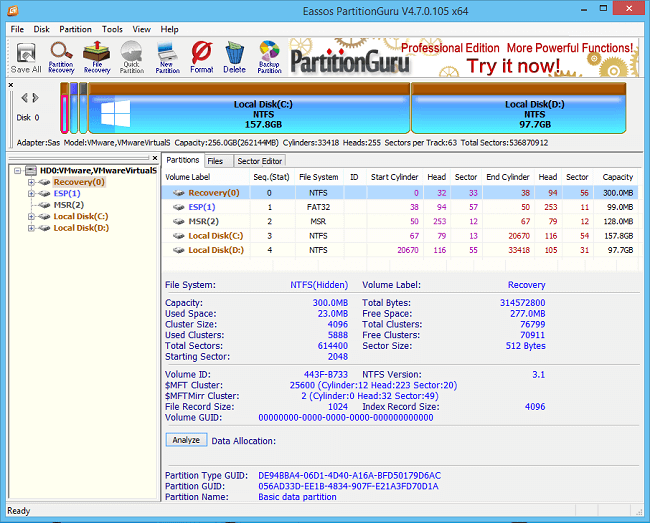
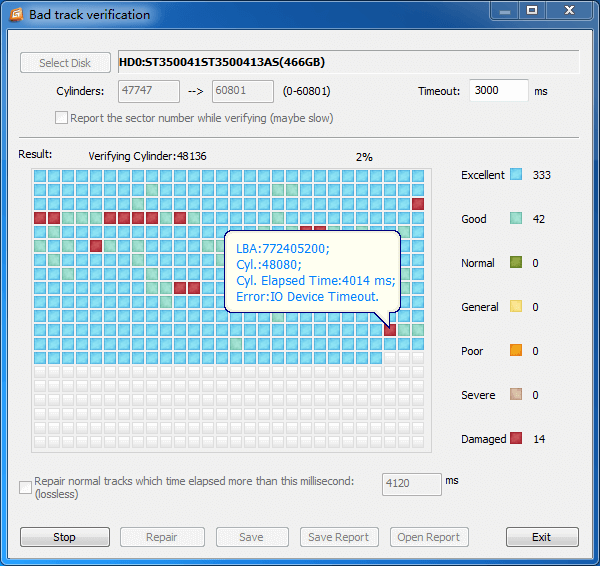
For example, the bad sectors indicated in the image above are from a drive that Hard Disk Sentinal Pro estimates has 21 days of life remaining. Two months ago it was reporting 30 days and I am still waiting to see how much longer it will go before it finds its way to data heaven. So it does show that predictive analysis, while indicating that data is at risk, still cannot accurately give a reliable idea of how much time it has remaining.
Even though the bad sector count has not increased in months and using HDD Regenerator on the drive to see if it could revive those 77 bad sectors didn’t help, the overall health has still decreased somewhat. It’ll be interesting to see how much longer it survives.